雪花ID
世界上,没有完全相同的两片雪花。这就是雪花算法这个名称的由来。雪花算法(SnowFlake)是Twitter公司发明的一种算法,主要目的是解决在分布式环境下,ID怎样生成的问题。

在正常的业务开发中,数据库中的主键或者唯一键,都需要生成一个唯一标识,如用户id、订单id、订单编号等。
那么雪花算法是如何保证在高并发的情况下,能够保证不重复呢?
雪花ID解决的问题
分布式环境下ID如何生成的问题
反爬虫
如果ID是从1开始递增,那么网络爬虫可以根据ID从1开始顺序抓取数据。
所以面对外部用户可见的数据(比如帖子),更长的、递增的、不连续的ID,而其中最典型的就是雪花算法
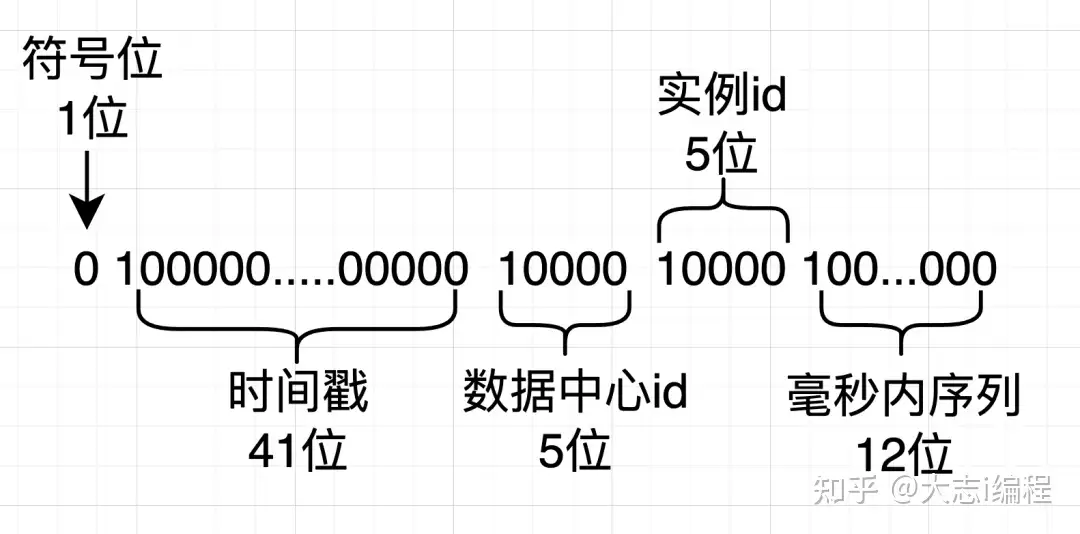
雪花ID的组成
在Java中表示雪花算法生成的id,需要使用Long类型,雪花算法是由1位符号位,0表示正数,1表示负数,id一般都是正数。
接下来的41位为一个毫秒级时间戳,这个时间戳存储的并不是当前时间,而是当前时间戳与指定的时间戳之间的差值,即指定时间戳 – 当前时间戳。
10位的数据机器位,可以表示2的10次方,即1024个节点,其中包括五位数据中心id和五位工作节点id。
12位毫秒内的计数器,支持统一机器同一时间戳产生4096个id序号。
以上数据合在一起刚好64位,即一个Long型数据。